Generative AI has become one of the fastest moving areas in technology. What started as small experiments with chatbots and image generators has now turned into a wave of adoption inside organizations. Employees use consumer apps like ChatGPT or Midjourney to spark ideas, business units sign contracts with enterprise vendors that embed AI into existing software, and engineering teams explore how to plug pre-trained or fine-tuned models into their own applications.
This rapid adoption comes with a challenge that every security professional will recognize: responsibilities are often unclear. Who owns the risks if an employee uploads sensitive data into a consumer app? What guarantees do we actually get when signing an enterprise contract with an AI vendor? At what point does our organization become responsible not just for how an application uses AI, but for the security of the model itself?
To bring clarity to these questions, AWS introduced the Generative AI Security Scoping Matrix at re:Inforce 2024. Although the model originated at AWS, I believe its value goes beyond a single provider. It offers a straightforward way to frame conversations about generative AI security: what we are buying, what we are building, and where the line of responsibility lies.
In this post, I’ll share my own perspective on the matrix. I’ll walk through the five different scopes of generative AI adoption, outline the security disciplines that apply to each, and highlight some common practices that remain important no matter which scope you fall into.

Why a Security Scoping Matrix Matters
When generative AI entered the workplace, it created both excitement and confusion. Many organizations saw employees experimenting with public tools on their own, without clear approval. Others rushed to buy enterprise products with AI features, even before understanding how the data would be handled. Security teams often reacted in two ways: either by blocking everything to stay safe, or by letting adoption grow without proper boundaries.
Both reactions bring problems. If you block AI completely, people will still use it secretly. This is what we call shadow IT. When that happens, you lose visibility into where data goes and what risks exist. On the other hand, if you allow AI without any control, you may end up exposing sensitive data or relying on services you do not fully trust.
This is where the Generative AI Security Scoping Matrix becomes useful. It does not try to give one single answer for all use cases. Instead, it helps you ask a better question: in this specific case, what do we own and what does the provider own? By scoping correctly, you can decide which risks are acceptable, which controls you need, and how to communicate this clearly to your users and business leaders.
In simple words, the matrix gives us a common language. Developers, compliance officers, lawyers, and security architects can all look at the same scope and understand the boundaries. This avoids endless debates and lets teams focus on building secure solutions rather than arguing about who should be responsible.
Scope 1: Consumer AI Applications
Scope 1 is about public, consumer-grade AI applications. These are tools like ChatGPT, Midjourney, or PartyRock. They are usually easy to access with only a web browser or a mobile app. Sometimes they are free, sometimes they come with a subscription, but in all cases they are not designed for enterprise use.
In this scope, you as an organization have almost no control. You do not own or see the training data. You cannot influence how the model works. You can only type your prompt and read the response. That means the provider controls almost everything, and you are mainly responsible for your own input and how you use the output.
From a security perspective, this brings a few clear rules. Do not enter sensitive data like PII, confidential business information, or company IP. Treat everything you type as if it becomes public. Also, do not fully trust the output. There is no service-level agreement, no guarantees of accuracy, and no legal protection for how the results are used.
For many companies, the right approach is not to ban these apps completely, but to write simple guidelines. Tell employees what is acceptable and what is not. Educate them that using a consumer app for quick brainstorming is fine, but using it for customer data or regulated information is not. This reduces the risk of shadow IT and keeps adoption under control.
The data flow diagram for a generic Scope 1 consumer application is shown below. The color coding indicates who has control over the elements in the diagram: yellow for elements that are controlled by the provider of the application and foundation model (FM), and purple for elements that are controlled by you as the user or customer of the application. In Scope 1, the customer controls only their own data, while the rest of the scope—the AI application, the fine-tuning and training data, the pre-trained model, and the fine-tuned model—is controlled by the provider.
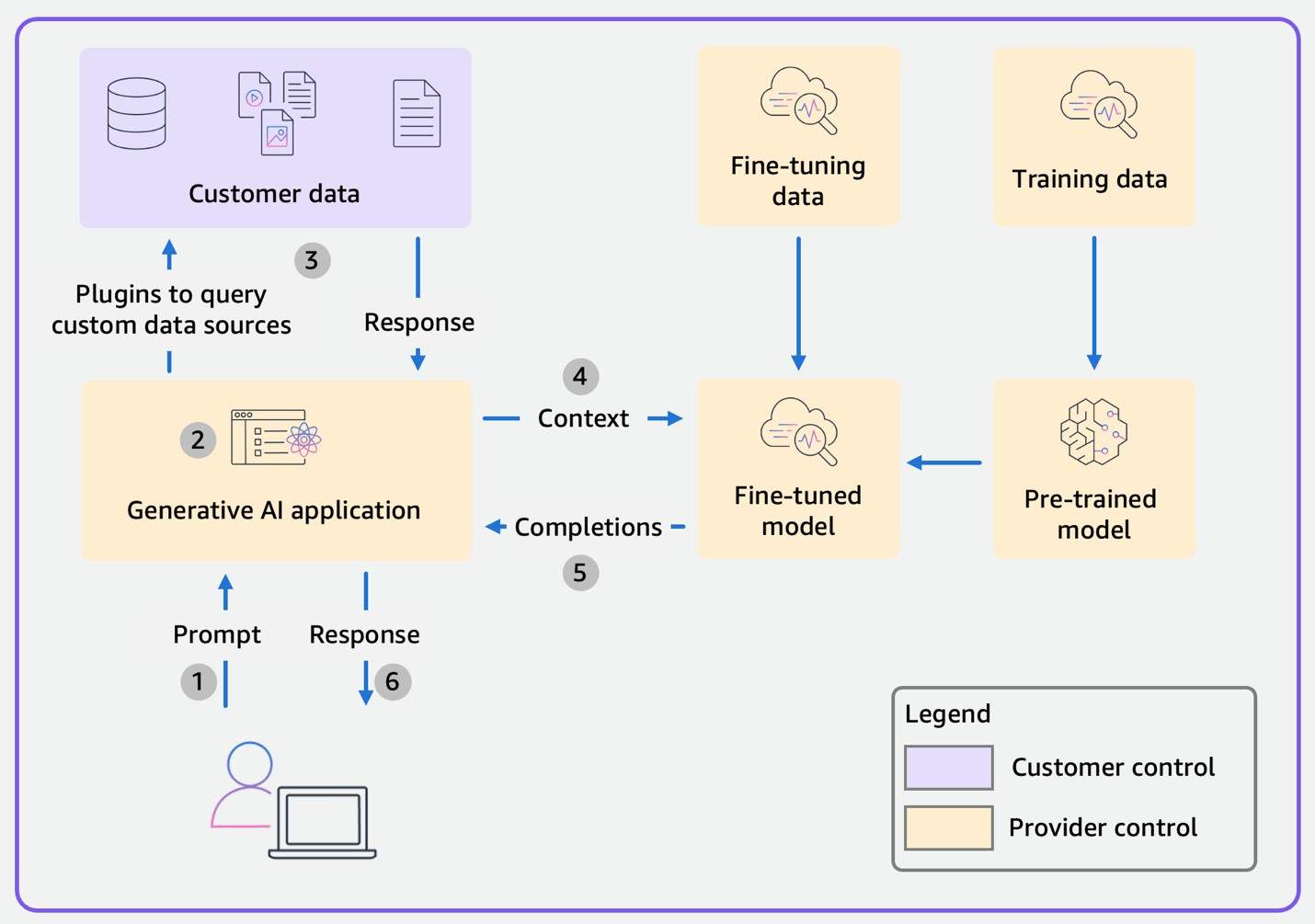
Scope 2: Enterprise AI Applications
Scope 2 is when you move from consumer apps to enterprise products that have generative AI features. Examples include Salesforce Einstein GPT or Amazon Q. The main difference from Scope 1 is that here you have a formal relationship with the vendor. There is usually a contract, an enterprise agreement, or at least business terms that define how the service is used.
This already changes the risk picture. You can expect the provider to offer some guarantees, like availability through SLAs, or options to control data sharing. You may also be able to configure access controls, integrate with your enterprise identity system, and align usage with your compliance policies.
Still, this does not mean all problems are solved. You must carefully review the provider’s terms of service, data residency, and privacy policies. Check if your enterprise data might be used to train the vendor’s models, and if you can opt out. Confirm where the data is stored and processed, especially if your organization has geographic or regulatory restrictions.
The key advice for Scope 2 is: do not just trust the marketing slides. Involve legal, compliance, and procurement teams when signing contracts. Make sure the use of enterprise AI apps matches your own data classification and governance rules. Security teams should also validate that identity context and access controls are enforced properly inside the application.
The data flow diagram for a generic Scope 2 enterprise application is shown below. If you recall, the flow is very similar to Scope 1. The color coding again shows the split of responsibilities: yellow for what the provider controls, purple for what you as the customer control. In Scope 2, the main difference from Scope 1 is not the flow itself but the existence of a business contract, giving you slightly more leverage and clarity.
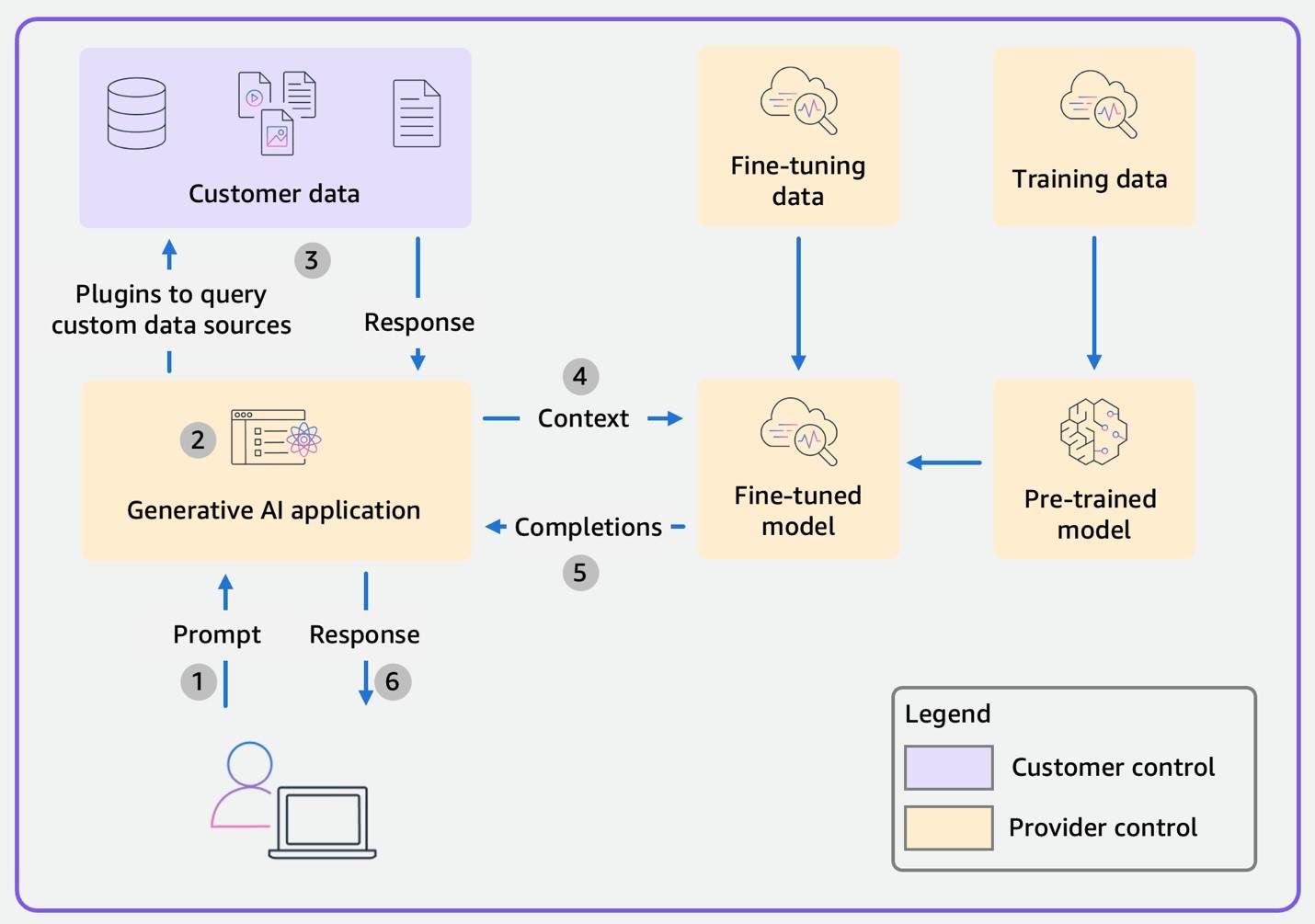
Scope 3: Pre-trained Models
Scope 3 is when your organization starts to build its own generative AI application, but instead of training a model yourself, you use a pre-trained foundation model. Services like Amazon Bedrock provide access to different foundation models through APIs. This lets you focus on building the application and using your own data, while the provider still takes care of the model and its training data.
In this scope, the balance of responsibility starts to shift. You control the customer data and the application logic. You decide how to structure prompts, what information is pulled from your internal systems, and how the outputs are handled. The provider still owns and manages the foundation model, but you are now responsible for securing how the model is used inside your application.
From a security point of view, this is where things get more serious. You need to protect your data before it is sent to the model, and also validate the output before it reaches your users. Attacks like prompt injection, data leakage, or model inversion become relevant. Strong access controls on the model endpoints, encryption of traffic, and careful monitoring are all necessary. You may also consider techniques like Retrieval Augmented Generation (RAG) to improve accuracy by enriching prompts with your own trusted data.
In Scope 3, your organization is building a generative AI application using a pre-trained foundation model such as those offered in Amazon Bedrock. The data flow diagram for a generic Scope 3 application is shown below. The change from Scopes 1 and 2 is that, as a customer, you control the application and any customer data used by the application while the provider controls the pre-trained model and its training data.
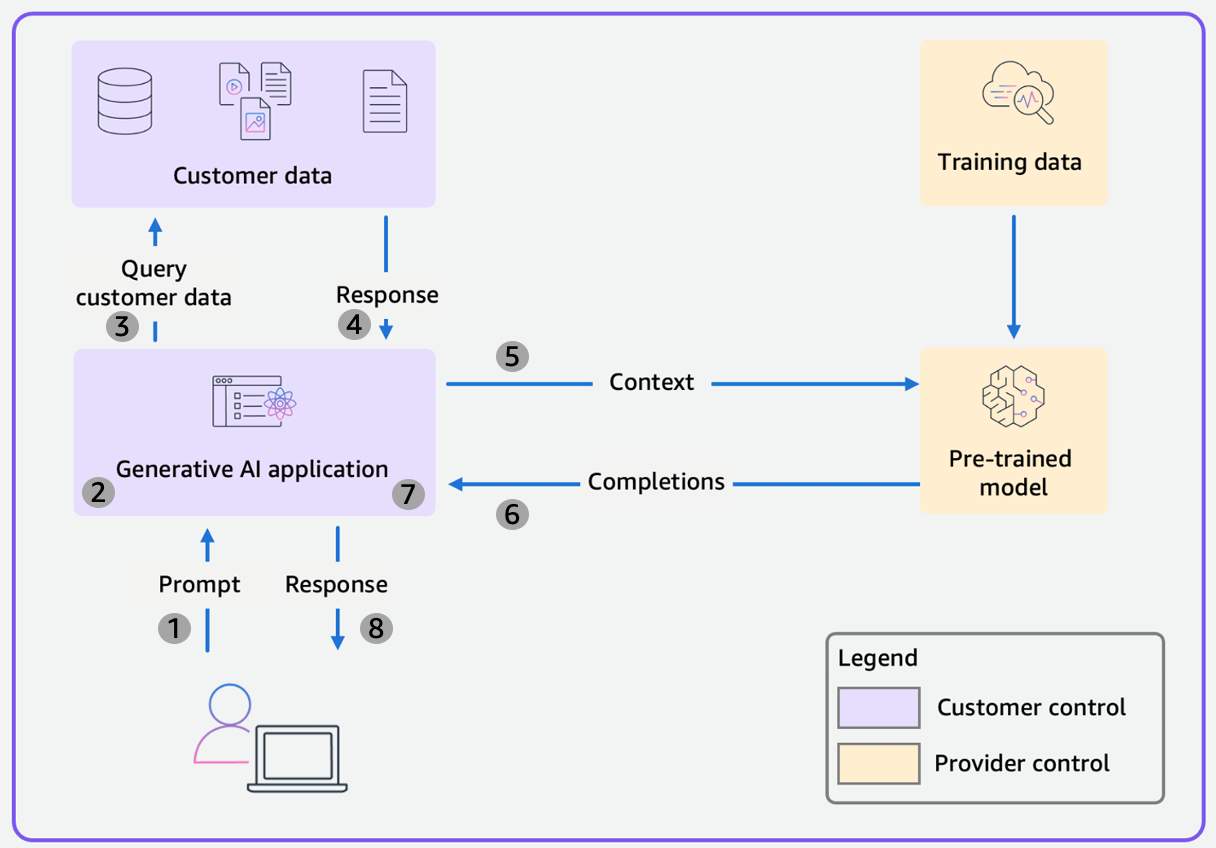
Scope 4: Fine-tuned Models
Scope 4 is the stage where you take an existing foundation model and adapt it to your own business needs. Instead of using the pre-trained model as-is, you fine-tune it with your own data so the model performs better in your specific domain. For example, a hospital might fine-tune a foundation model with electronic health records so that it understands medical terminology and produces outputs more aligned with clinical needs.
Here, your responsibility grows compared to Scope 3. You now own not only the customer data and the application, but also the fine-tuning process and the resulting fine-tuned model. This means you need clear policies for data selection, strong access controls around the fine-tuning environment, and processes for testing and validating the model before deployment.
The risks also increase. If the fine-tuning data contains sensitive information or personally identifiable information (PII), it can be very hard to “unlearn” once the model has been trained. There is also the chance of overfitting, bias, or even poisoning attacks if the fine-tuning data is not properly secured and reviewed. Intellectual property questions also come up more often: who owns the fine-tuned model, and what restrictions still apply from the original foundation model license?
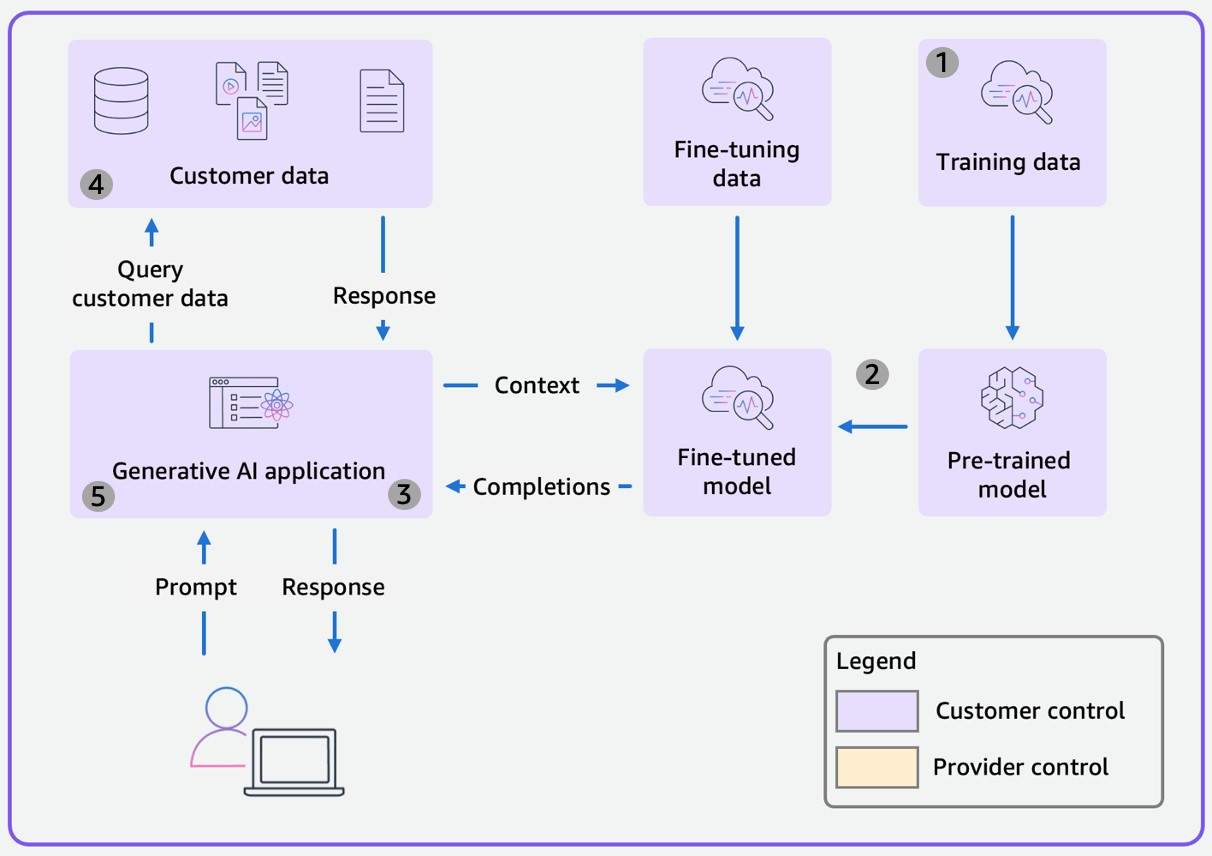
In Scope 4, you fine-tune a foundational model (FM) with your data to improve the model’s performance on a specific task or domain. When moving from Scope 3 to Scope 4, the significant change is that the FM goes from a pre-trained base model to a fine-tuned model as shown below. As a customer, you now also control the fine-tuning data and the fine-tuned model in addition to customer data and the application. Because you’re still developing a generative AI application, the security controls detailed in Scope 3 also apply to Scope 4.
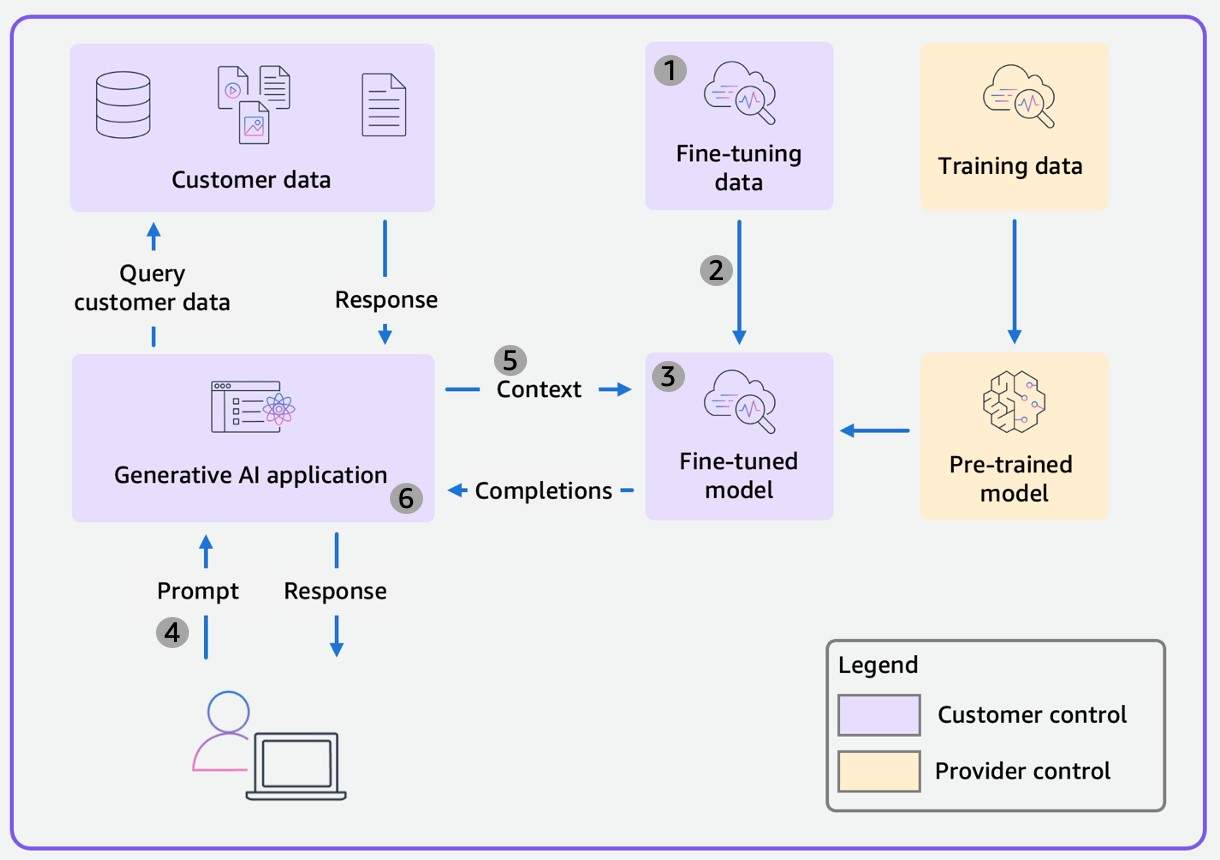
Scope 5: Self-trained Models
Scope 5 is the most advanced and complex stage. In this scope, your organization trains a foundation model completely from scratch, using your own or acquired data. You decide on the architecture, the training process, and the infrastructure. This is the opposite end of the spectrum compared to Scope 1: you control everything, but you also take on all the responsibility.
This path is only realistic for organizations with a strong business reason to justify the enormous cost, time, and expertise required. Think about industries that need very specialized models, like advanced video generation, pharmaceutical research, or defense. Training such models requires not only massive computing power, but also very large and carefully curated datasets.
The security implications are heavy. You must secure every stage of the pipeline from collecting and cleaning training data, to storing and processing it securely, to managing access during training and deployment. You also need policies for versioning, updating, and decommissioning models, because once trained, a model inherits the classification of its training data and may contain sensitive information that cannot easily be removed.
In Scope 5, you control the entire scope, train the FM from scratch, and use the FM to build a generative AI application as shown below. This scope is likely the most unique to your organization and your use cases, and it requires both deep technical capabilities and a strong business case to justify the cost and complexity.
It is important to note that very few organizations will actually operate in Scope 5. The amount of training data, compute resources, and specialized expertise needed is beyond the reach of most companies. For most organizations, Scope 2, Scope 3, or sometimes Scope 4 will cover their needs.
That said, Scope 5 is included for completeness. It shows the far end of the spectrum, where all responsibilities fall on the organization itself. Unlike predictive AI, where training your own models on proprietary data is common, generative AI foundation models are much more demanding. If you take this path, you also inherit all responsibilities normally handled by a model provider from collecting training data (and ensuring you have the legal right to use it), to filtering out biased or unsafe content, to monitoring for misuse and maintaining the full lifecycle of the model.
Security Disciplines Across All Scopes
Regardless of whether you are experimenting with a consumer app (Scope 1) or building your own model from scratch (Scope 5), there are certain security areas that apply everywhere. These are the disciplines that guide how you manage risk, build trust, and keep control as you scale generative AI. The depth and complexity will change depending on the scope, but the fundamentals remain the same.
- Governance & Compliance: Governance starts with setting clear policies. Who is allowed to use AI tools, and for what kind of data? How are outputs validated before being used in business processes? At enterprise level, governance also means continuous monitoring and reporting. Many industries now face evolving AI regulations, like the EU AI Act or sector-specific guidance in healthcare and finance. Even if you are only in Scope 2, your organization should already map AI usage to regulatory obligations. Without governance, adoption quickly becomes inconsistent and risky.
- Legal & Privacy: Every scope brings legal and privacy questions. For Scope 1, the issue is that consumer apps can change their terms at any time, and you may have no rights over the outputs. In Scope 2, contracts give you more clarity, but you still need to check data residency and ensure you can opt out of vendor training. For Scopes 3–5, the responsibility shifts heavily to you: do you have the rights to use the data for training or fine-tuning? Are you protecting personally identifiable information (PII) with anonymization or other techniques? And if your organization releases outputs externally, do you know the copyright and licensing implications? Privacy and legal checks cannot be left to chance.
- Risk Management: Generative AI introduces both old and new risks. Traditional risks like third-party dependency still apply in Scopes 1 and 2, but as you move toward Scopes 3–5, new risks like prompt injection, data leakage, or model drift appear. Some risks are subtle: for example, if a fine-tuned model is overfit on sensitive internal data, it may accidentally leak that data through outputs. Strong risk management means performing threat modeling, extending your vendor risk assessments to AI services, and regularly reviewing risks as adoption grows.
- Security Controls: Controls are where policies and risk strategies become real. In Scopes 1 and 2, this may mean using CASB, proxies, or DLP solutions to limit what data goes into consumer or enterprise apps. In Scopes 3–5, you need more advanced technical safeguards: encrypting traffic to model endpoints, authenticating users through enterprise identity systems, applying least privilege access, and validating both inputs and outputs. A good rule of thumb is to treat generative AI applications as part of your core IT infrastructure; they deserve the same monitoring, logging, and defensive layers as any other business-critical system.
- Resilience: Finally, resilience is about keeping systems reliable even when things go wrong. Consumer apps (Scope 1) may not offer any SLA, so you should not build critical workflows around them. Enterprise apps (Scope 2) usually provide SLAs, but you still need fallback plans for outages. In Scopes 3–5, resilience also covers model versioning, drift detection, and retraining strategies. A resilient design includes backups of prompts and outputs, graceful degradation when APIs fail, and clear incident response plans. Without resilience, even a short outage or a model update can disrupt business processes in unexpected ways.
Taken together, these five disciplines are the backbone of the Generative AI Security Scoping Matrix. They are not optional, they apply in every scope. What changes is the level of control and responsibility you hold. As you move from Scope 1 toward Scope 5, the weight of governance, legal, risk, controls, and resilience shifts more and more onto your organization.
Common Guidance (Applies Everywhere)
No matter which scope you are in, some practices stay important everywhere. These are not new ideas, but they become even more critical with generative AI. Think of them as the “security basics” that need to be applied with discipline.
- Data classification and handling: Always know what type of data is being used. If you don’t want it to end up in the wrong place, mark it clearly and make sure users understand the rules. For consumer apps, that means never entering confidential data. For enterprise or custom apps, it means aligning prompts, outputs, and training data with your organization’s classification policy.
- Access control and identity management: Limit who can use AI applications and what they can access. The principle of least privilege applies here too. Integrating enterprise identity (SSO, MFA, RBAC) helps ensure the right people see the right data in the right context.
- Encryption and key management: Protect sensitive data both at rest and in transit. Use strong encryption standards and centralized key management. This is especially important in Scopes 3–5 where you directly manage applications, storage, and model endpoints.
- Monitoring, logging, and anomaly detection: Generative AI introduces new behaviors, so monitoring is key. Log access, model usage, and data flows. Watch for unusual prompts or outputs that might indicate misuse or prompt injection. Having logs also helps with incident response and compliance reporting.
- Input/output validation: Do not trust inputs or outputs blindly. Malicious prompts can manipulate models, and outputs can contain harmful, biased, or simply incorrect content. Use filtering, content moderation, or post-processing checks to keep control.
- Incident response planning: Finally, be ready for when something goes wrong. A clear plan with defined roles and escalation paths will save time and reduce damage. For AI-specific incidents, think about model drift, output misuse, or exposure of sensitive data.
In short, securing generative AI is not only about new tools or fancy methods. It is mostly about applying old, well-known security practices consistently in this new context. If your basics are solid, handling the unique challenges of generative AI becomes much easier.
Key Takeaways for Organizations
Most organizations today are not training large models from scratch. In practice, most activity happens in Scope 2 (Enterprise AI Applications) and Scope 3 (Pre-trained Models). These are the areas where companies can get real business value quickly, but also where clear responsibilities need to be defined.
Another important point is that regulations are moving fast. The EU AI Act, GDPR, CCPA, and other privacy or sector rules all shape what is acceptable. Even if your organization is only experimenting with consumer apps, it is better to prepare now instead of reacting later when compliance checks arrive.
The Generative AI Security Scoping Matrix is not a set of rules, but a way to frame the conversation. It helps you ask the right questions:
- Who owns the data?
- Who is responsible for outputs?
- What guarantees do we have about reliability and privacy?
- How do we keep adoption aligned with governance and compliance?
By using the matrix, security teams, developers, and business leaders can speak the same language. Instead of endless debates about “should we allow generative AI or not,” the conversation becomes: “Which scope are we in, and what responsibilities do we need to take?”
In short:
- Start with awareness → know which scope your current use cases fall into.
- Strengthen your fundamentals → apply common guidance like data classification, access controls, and monitoring.
- Engage across teams → legal, compliance, and procurement should be part of AI adoption.
- Plan for growth → even if you are in Scope 2 today, your organization may move toward Scope 3 or 4 tomorrow.
The organizations that succeed with generative AI will not be the ones that try to ban it or run after every new tool. They will be the ones that scope it correctly, apply the right security practices, and grow adoption in a controlled and responsible way.
Conclusion
Generative AI brings big opportunities, but it also changes how we think about security responsibilities. The Generative AI Security Scoping Matrix is a simple way to make sense of it. As you move from buying (Scopes 1 and 2) to building (Scopes 3–5), the balance of responsibility shifts more and more onto your organization.
The framework is not about banning tools or slowing innovation. It is about creating clarity: knowing what you control, what the provider controls, and how to apply the right security disciplines across the lifecycle. With this clarity, teams can avoid shadow IT, align with regulations, and adopt AI in a way that is both secure and useful for the business.
My advice is simple: take a moment to map your current and planned AI initiatives into the five scopes. This small exercise often brings surprising insights and helps highlight where gaps may exist. Once you know the scope, it becomes much easier to define policies, controls, and responsibilities.
In the end, successful AI adoption is not only about models or algorithms. It is about trust. By scoping correctly and applying security fundamentals, organizations can build that trust and move forward with confidence.
References
- AWS Generative AI Security Scoping Matrix - Official AWS framework for AI security scoping
- Securing Generative AI: An Introduction to the Generative AI Security Scoping Matrix - AWS Security Blog implementation guide
- AWS re:Inforce 2024: Accelerate Securely - The Generative AI Security Scoping Matrix - Conference presentation slides
- AWS re:Inforce 2024: Accelerate Securely - The Generative AI Security Scoping Matrix (Video) - AWS re:Inforce 2024
- AWS Whitepaper: Navigating the Security Landscape of Generative AI - Comprehensive security whitepaper