In Part 1 we set the foundation with deployment models and routing mechanics. In this blog post we narrow the lens to a single VPC and focus on placing inspection between subnets. The goal is simple: insert a control point without hairpins, keep paths symmetric, and make the data plane predictable at scale.
Why start inside one VPC
Most inspection problems show up first inside a VPC. As your service count grows, the default assumption that everything inside the VPC can talk to everything else becomes expensive during incidents and difficult to govern. Intra-VPC inspection gives you a way to segment, observe, and enforce policy inside the boundary without redesigning applications. The key is to place a clear insertion point in the data path and steer traffic through it intentionally.
Modern VPC routing lets you do this with ordinary route lookups. You can direct subnet-to-subnet flows through a Gateway Load Balancer endpoint for third-party appliances or through an AWS Network Firewall endpoint for a managed experience. No overlays, no custom NAT tricks, and no source rewrites. Once this is in place, security teams get visibility and control, and platform teams keep a simple, supportable path that scales with demand.
Pattern A: Subnet to subnet in the same Availability Zone
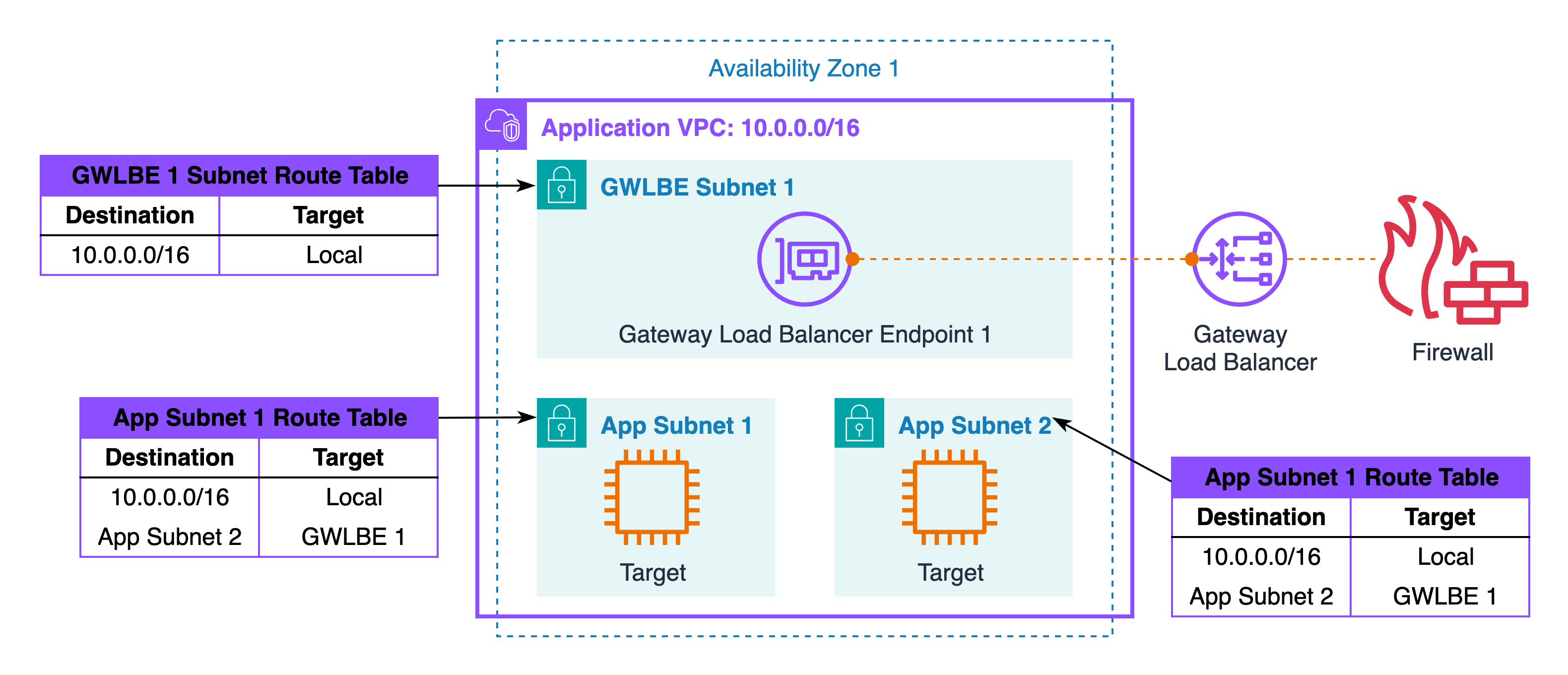
Two application subnets live in the same Availability Zone. You add an inspection subnet in that AZ and place a Gateway Load Balancer endpoint or a Network Firewall endpoint inside it. Each application subnet is then told to reach its peer through that endpoint. Both directions of the flow pass through the same insertion point, so stateful inspection remains stable and you do not need policy-based routing or hairpins.
Traffic walk-through
When an application in Subnet 1 initiates a connection to a target in Subnet 2, the packet is evaluated against Subnet 1’s path selection and selected for the inspection path. The first hop is the inspection endpoint in the same Availability Zone, where your policy engine evaluates the request and either forwards or drops it. If it is allowed, the inspected packet is forwarded toward Subnet 2 and delivered to the target workload without any hairpin or NAT side effects.
The return leg follows the same logic in reverse: Subnet 2 chooses the same inspection endpoint for traffic destined to Subnet 1, which means the device sees both directions of the flow and can keep state consistently. This holds true whether the initiator flips midstream due to application behavior or whether the traffic pattern alternates over time, because both participants always select the same insertion point for each other.
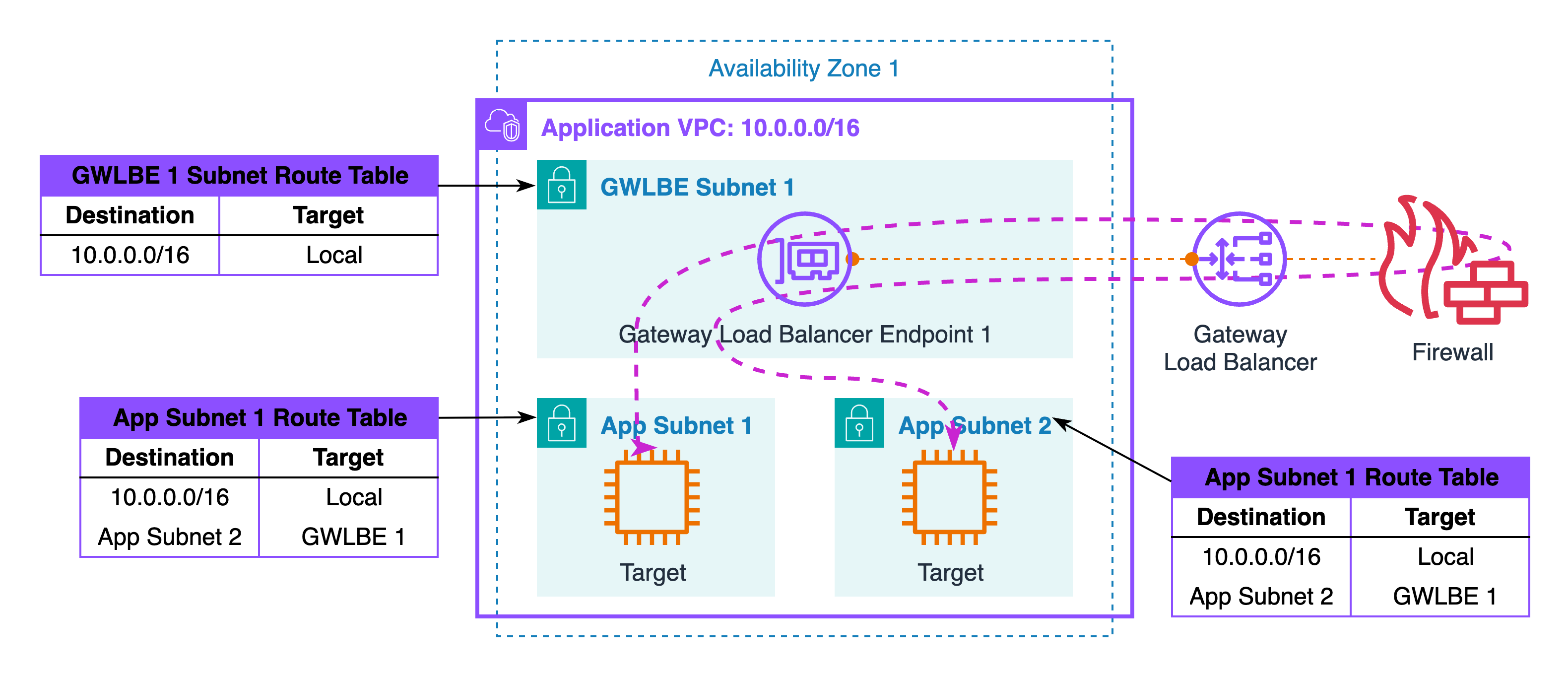
Security boundary and TLS choices
Inside one AZ you can place the inspection hop either before a load balancer or between the load balancer and its targets, and the right choice depends on what identity and content you need to see. Placing inspection before the load balancer preserves the original client IP and allows you to apply geo, reputation, and anomaly rules that depend on true source identity, although decrypting TLS here usually means handling public certificates and planning for secure key management.
Placing inspection between the load balancer and the targets narrows what you examine to traffic the load balancer has already accepted, which often reduces noise for application teams and allows you to use private certificates for decryption. Both placements are valid in this single-AZ pattern, and both benefit from the same routing capability; decide based on the visibility you need, the compliance posture around certificate handling, and the operational model your teams can support over time.
Validation without route tables
You can validate correctness without ever pasting a route table by testing intent from the edge inward. Start with a simple reachability check from Subnet 1 to Subnet 2 and confirm, through device telemetry or logs, that the connection traverses the inspection endpoint you expect. Repeat in the opposite direction to verify that the same session is observed on the device for both legs, which is the practical test for symmetry. Add a short soak test that generates sustained traffic between the subnets and watch for consistent throughput and stable session counts on the inspection tier. Finally, simulate a benign failure by draining one appliance behind the endpoint and confirm that flows continue through the same insertion point while the fleet scales or fails over as designed. If all of these observations align with your expectations, your VPC routing plan is correctly realized in the data path.
Common pitfalls to avoid
By far the most common mistake is leaving subnet-to-subnet traffic to follow the implicit local path, which bypasses inspection completely; the telltale sign is that the device never sees sessions for peers inside the same VPC.
A close second is accidentally placing the inspection endpoint in a different Availability Zone and paying for cross-AZ hops, which can break symmetry under load and inflate latency and cost. Teams also run into avoidable noise when they inspect before the load balancer without planning certificate operations and client IP attribution, or when they inspect after the load balancer and expect to see pre-LB signals that no longer exist.
Less obvious, but equally important, is treating the inspection subnet as a best-effort zone: without health checks, alarms, and unified logging, you will discover failures from user reports rather than from telemetry. Codify these lessons in a short runbook and you will keep the same-AZ pattern predictable and boring, which is exactly what you want for a control point.
Operational notes: keep everything zonal in this pattern. The application subnets, the inspection subnet, and the appliances that serve them should be in the same Availability Zone. This reduces latency, lowers cross-AZ data transfer, and keeps failures contained to the zone where they occur. Treat the inspection subnet like a proper tier. Name and tag it consistently, monitor capacity, and publish logs and metrics to the same destinations you use for the rest of the platform.
Also, with Gateway Load Balancer, health checks prune failed appliances automatically while preserving the same insertion point. With AWS Network Firewall, scaling and logging are service features you can standardize on.
Pattern B: Subnet to subnet across different AZs
Now the application subnets live in different Availability Zones. The requirement is the same as Pattern A: force both directions of a stateful conversation through a single, consistent inspection hop. The risk is asymmetry. If each side picks a different insertion point, half of the flow will miss state and you will see intermittent drops that are hard to diagnose. The simplest and most reliable answer is to fix a stable choice for each AZ pair and use that one endpoint for both directions of that pair.
Assume three Availability Zones named AZ1, AZ2, and AZ3. Each zone contains at least one application subnet and one inspection subnet. The inspection subnet hosts either a Gateway Load Balancer endpoint that fronts a pool of virtual appliances or an AWS Network Firewall endpoint if you want the managed tier. Everything is zonal by design so that data paths remain short and failure is contained within the same zone as the workloads. The control you are introducing is a simple pair-wise rule: for each pair of AZs, choose one inspection endpoint, and use that single endpoint for both directions of that pair. The choice is stable and does not depend on who initiates.
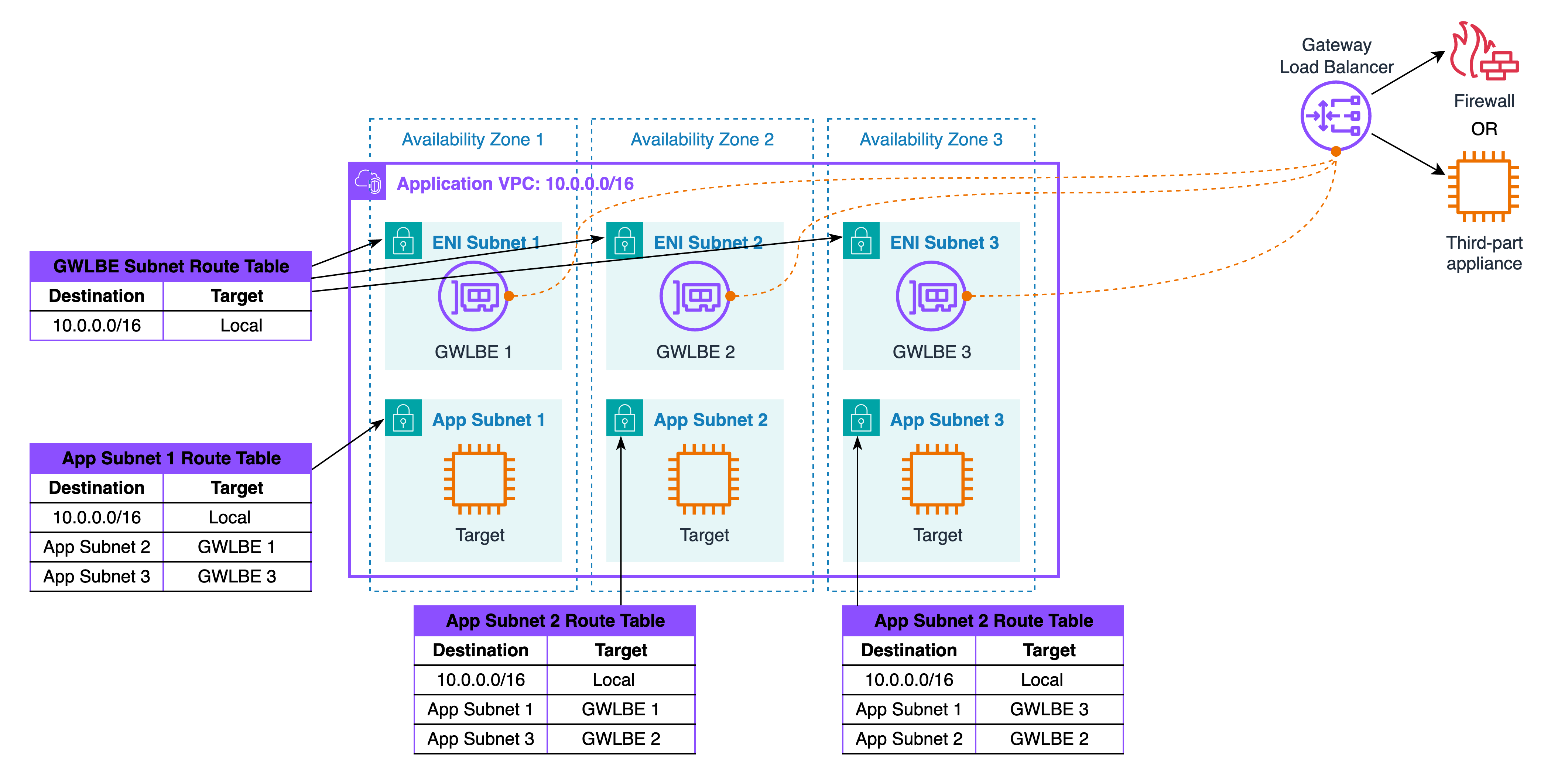
Traffic walk-through
Each AZ pair uses a single, fixed inspection endpoint, regardless of which side initiates. With that in mind, let’s trace through one AZ pair to see how this works. A workload in AZ1 opens a connection to a workload in AZ2. AZ1 evaluates its path selection, recognizes that the destination lives in AZ2, and selects the AZ1 inspection endpoint as the first hop. The inspection tier enforces policy and forwards the allowed packet toward AZ2 without hairpins or source rewrites. When AZ2 replies, it applies the same logic in reverse. Traffic that is destined back to AZ1 is also sent to the same AZ1 endpoint, so the device observes a single bidirectional session and maintains state cleanly. This remains true even if the application later flips initiators or alternates roles over time, because the insertion choice is tied to the pair, not to the direction.
Repeat the walkthrough for a second pair to show that the rule generalizes. A workload in AZ2 connects to a workload in AZ3. AZ2’s routing intent selects the AZ2 inspection endpoint as the first hop, the device evaluates policy, and the packet continues toward AZ3. The reply from AZ3 returns through that same AZ2 endpoint, so the inspection tier again sees one coherent, stateful conversation. Whether AZ3 initiates a new session back to AZ2 or the roles alternate during normal operation, the traffic continues to traverse the AZ2 insertion point for that pair. This gives you predictable symmetry and clean logging - both directions of the flow hit the same inspection point, and simpler troubleshooting because every flow between those two zones shows up under the same endpoint.
If you operate multiple application subnets within a zone, nothing changes in the walkthrough. All AZ1 subnets talking to AZ2 subnets still use the AZ1 endpoint, and all AZ2 subnets replying do the same. If an appliance behind an endpoint fails, Gateway Load Balancer or Network Firewall removes it from service while the insertion point remains unchanged, so the paths above hold without reconfiguration.
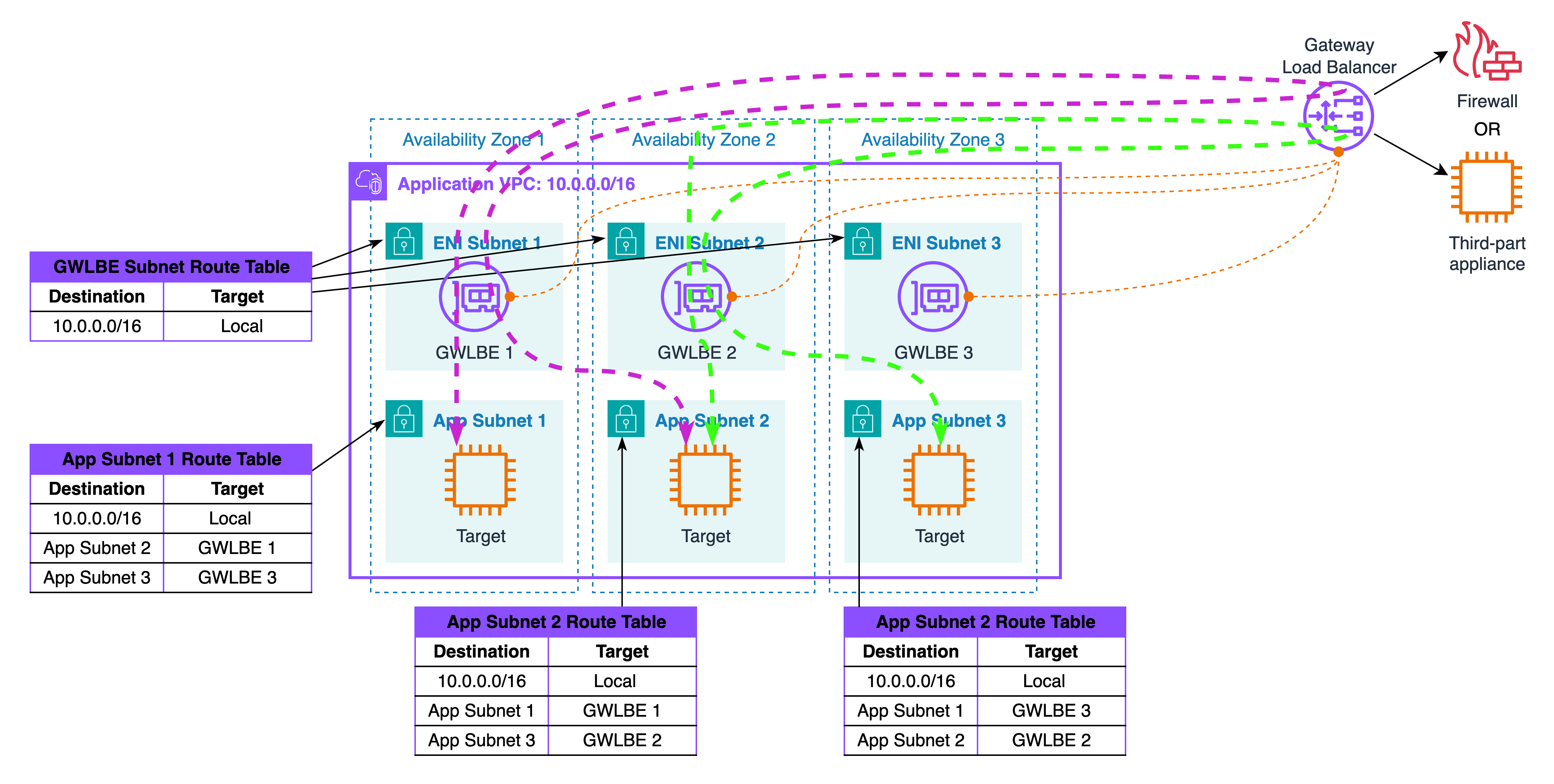
Security boundary and TLS choices
The same placement options from Pattern A still apply. If you insert inspection before a load balancer in one of the zones, you preserve the original client IP and can apply rules that depend on true source identity. You will also need a clear plan for handling public certificates if you decrypt TLS there. If you insert inspection between a load balancer and its targets, you examine only traffic the load balancer has already accepted, which usually lowers noise, and you can use private certificates for decryption. The pair-wise rule does not constrain which of these you select. It only guarantees that both legs touch the same endpoint.
Validation without route tables
Validate the design by testing intent rather than printing tables. First, run a reachability check from AZ1 to AZ2 and confirm, through device telemetry or logs, that the path enters the AZ1 endpoint. Repeat from AZ2 to AZ1 and verify that the same session is observed on the device for the return leg. Then perform the same checks for your other pairs, for example AZ2 to AZ3. Add a brief soak test to generate steady traffic and watch that throughput and session counts remain stable at the chosen endpoint. Finally, simulate a benign failure by draining one backend behind the endpoint and confirm that flows continue without the insertion point changing.
Failure thinking: The rule aligns inspection availability with application availability. If a single appliance behind a Gateway Load Balancer becomes unhealthy, the load balancer removes it but the insertion point remains the same. If an entire AZ fails, the pair that depends on that AZ’s endpoint is unavailable, which mirrors how most applications behave under a zonal event. This prevents surprise cross-AZ detours during incidents and keeps both latency and cost predictable.
Common pitfalls to avoid
Most stability problems come from violating the pair-wise rule. If each side of a pair references a different insertion point, you will see intermittent drops and hard-to-reproduce timeouts. Another frequent mistake is allowing a new application subnet to be created without applying the two specific destinations that reference the correct endpoint for its pairs. Both issues are solved by keeping the pair mapping in code, by naming and tagging endpoints with their AZ identity, and by running a short reachability test whenever a subnet or CIDR changes. Finally, resist the temptation to centralize inspection for cross-AZ traffic in a single zone. That shortcut introduces cross-AZ hairpins, weakens symmetry under load, and increases costs without improving control.
Operational checklist: monitor endpoint health and per-AZ capacity, not just appliance CPU. Alert if you stop seeing accepted flows for a known pair or if drops spike at one insertion point while others remain stable. Keep a short break-glass procedure that explains how to temporarily bypass a pair’s endpoint if you need to isolate a faulty device, and document the steps to restore the mapping once you have fixed the issue. As you add a fourth AZ, extend the mapping with three new pairs, bring up one inspection subnet and endpoint in that AZ, and apply the same rule. No other design change is required.
Observability and logging
Plan observability at the same time you design placement. Start by deciding what you want to be able to answer during an incident. Typical questions include who talked to whom, through which inspection hop, under which policy rule, and with what outcome. From those questions derive the fields you must log. At a minimum you will want the connection five-tuple, the decision taken by the inspection tier, the identifier of the endpoint or appliance that made the decision, and the Availability Zone. Add correlation fields such as request IDs from the load balancer and any internal trace IDs used by your platform. With that schema in mind, configure logging on the inspection tier, enable VPC Flow Logs on the subnets that participate in the pattern, and ensure load balancer logs are enabled where relevant. Send everything to a central destination with a consistent index or table layout so you can pivot quickly during investigations.
What’s next
This post focused on intra-VPC patterns within a single VPC. In the next post, we’ll expand to inter-VPC traffic inspection patterns, covering how to inspect traffic between different VPCs using Transit Gateway and Cloud WAN, and how to maintain symmetry across VPC boundaries.
For additional learning, check out the AWS Well-Architected Framework Security Pillar and AWS Security Best Practices for network security guidance.